

友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
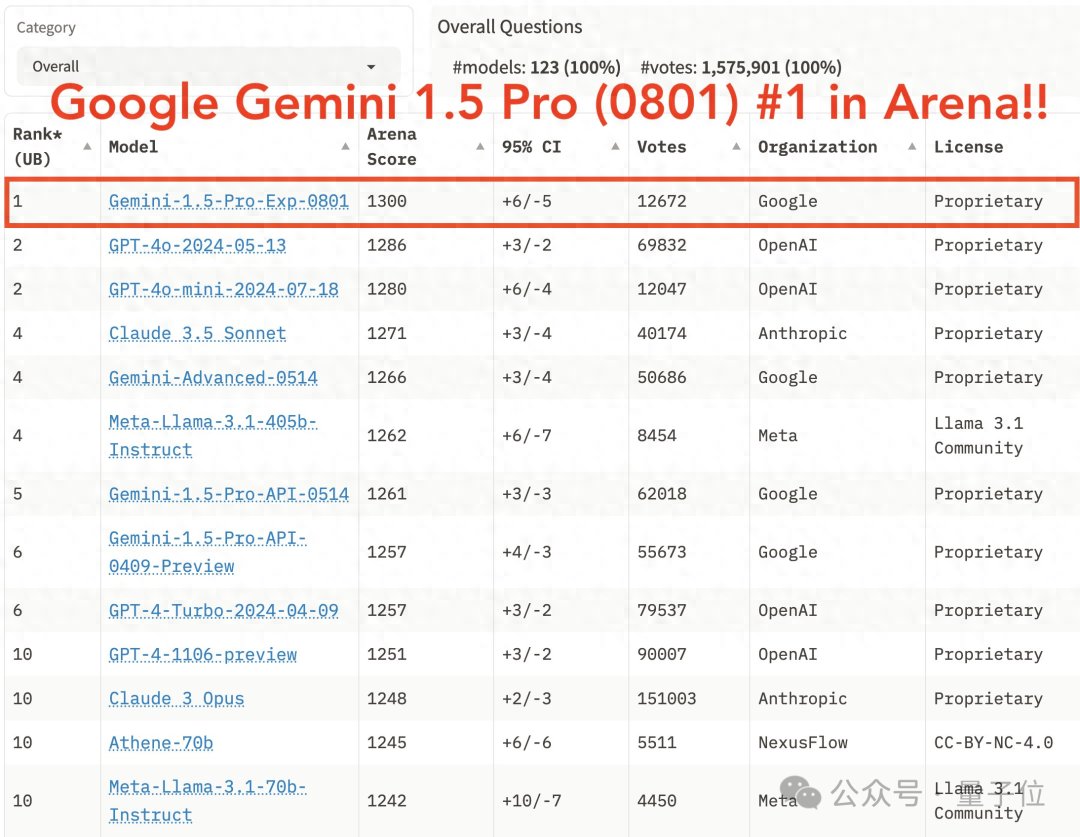
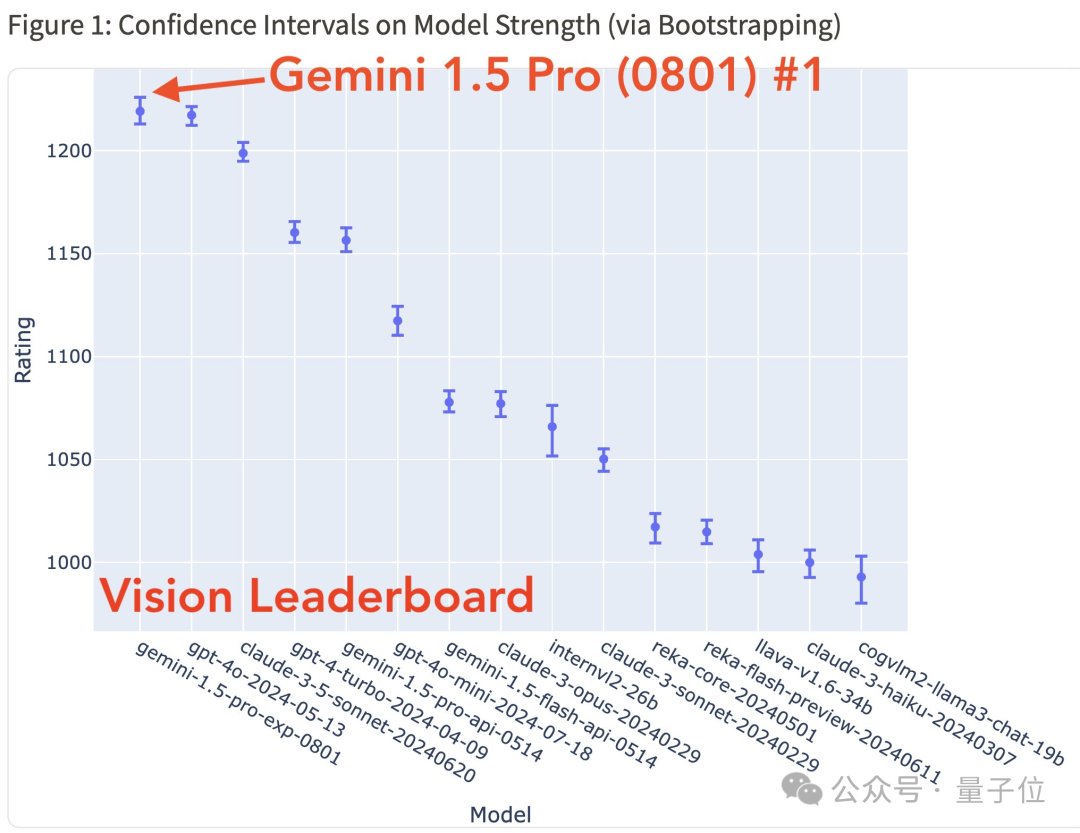
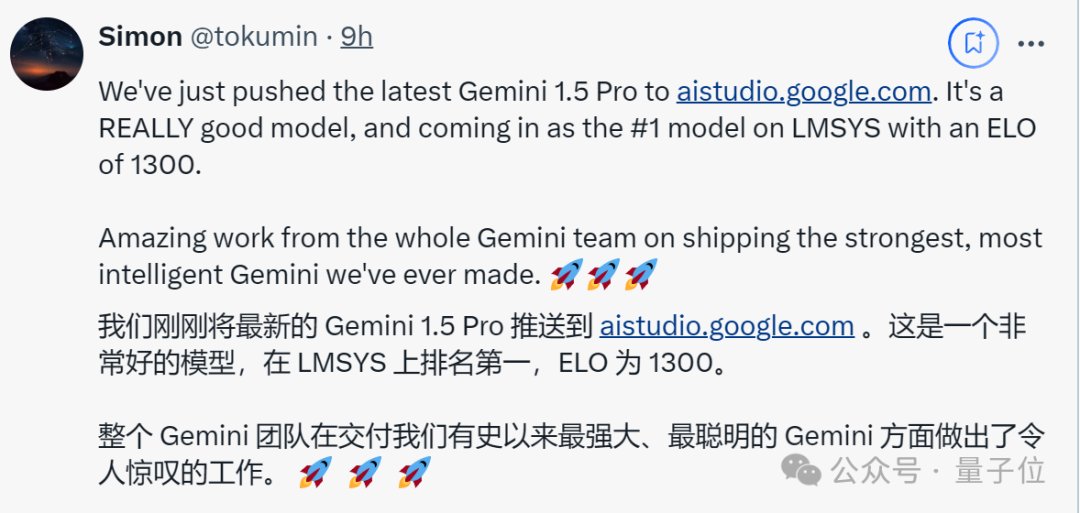
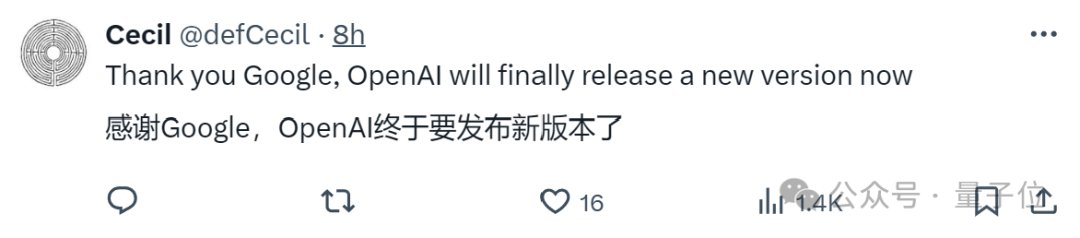
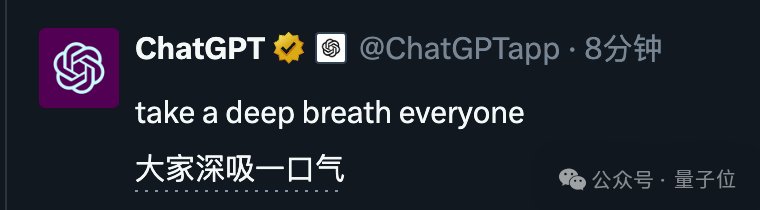
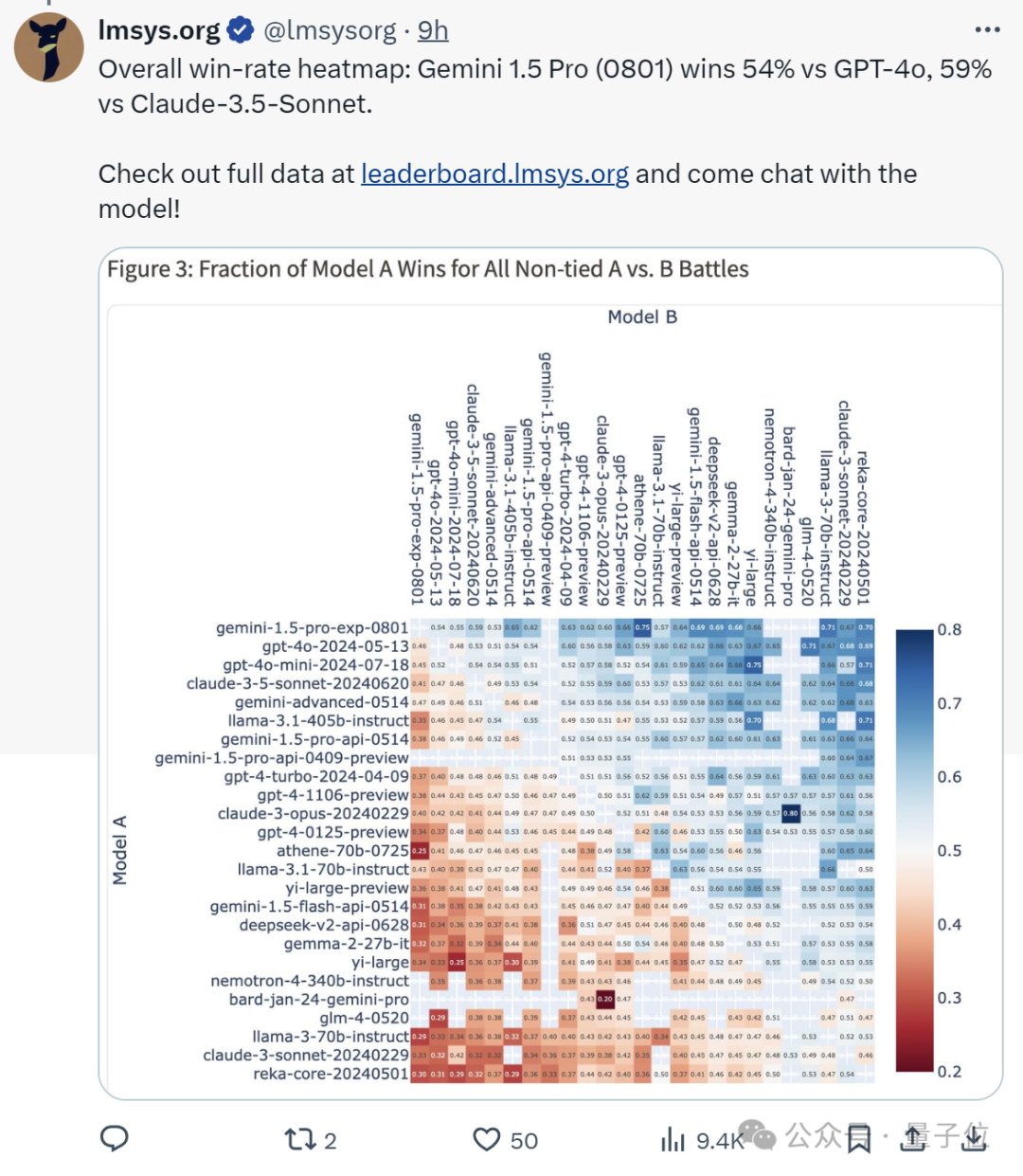
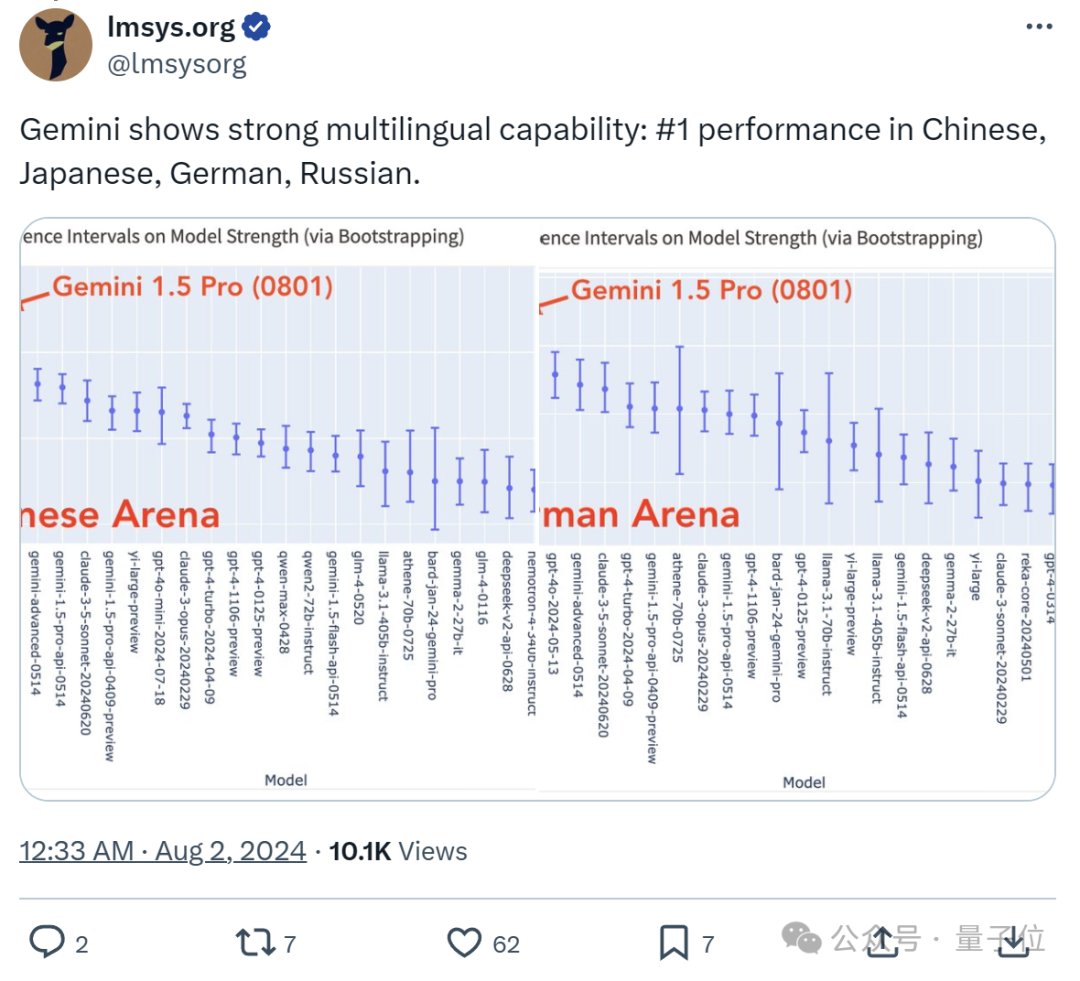
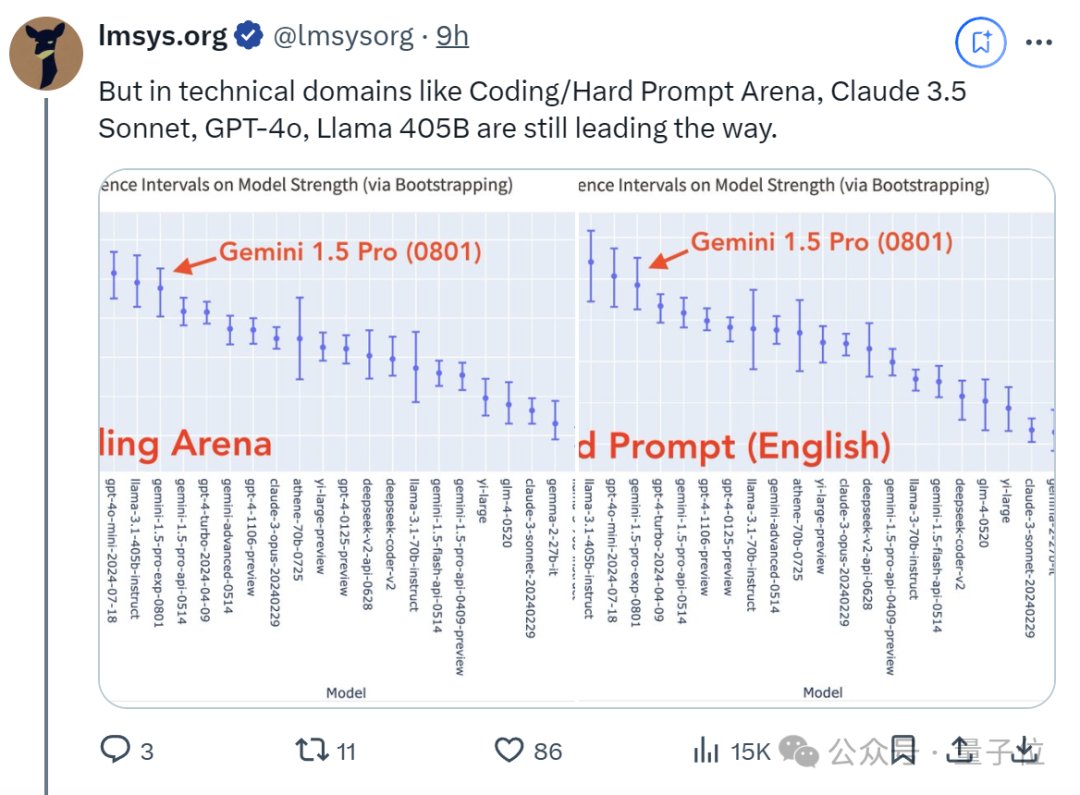
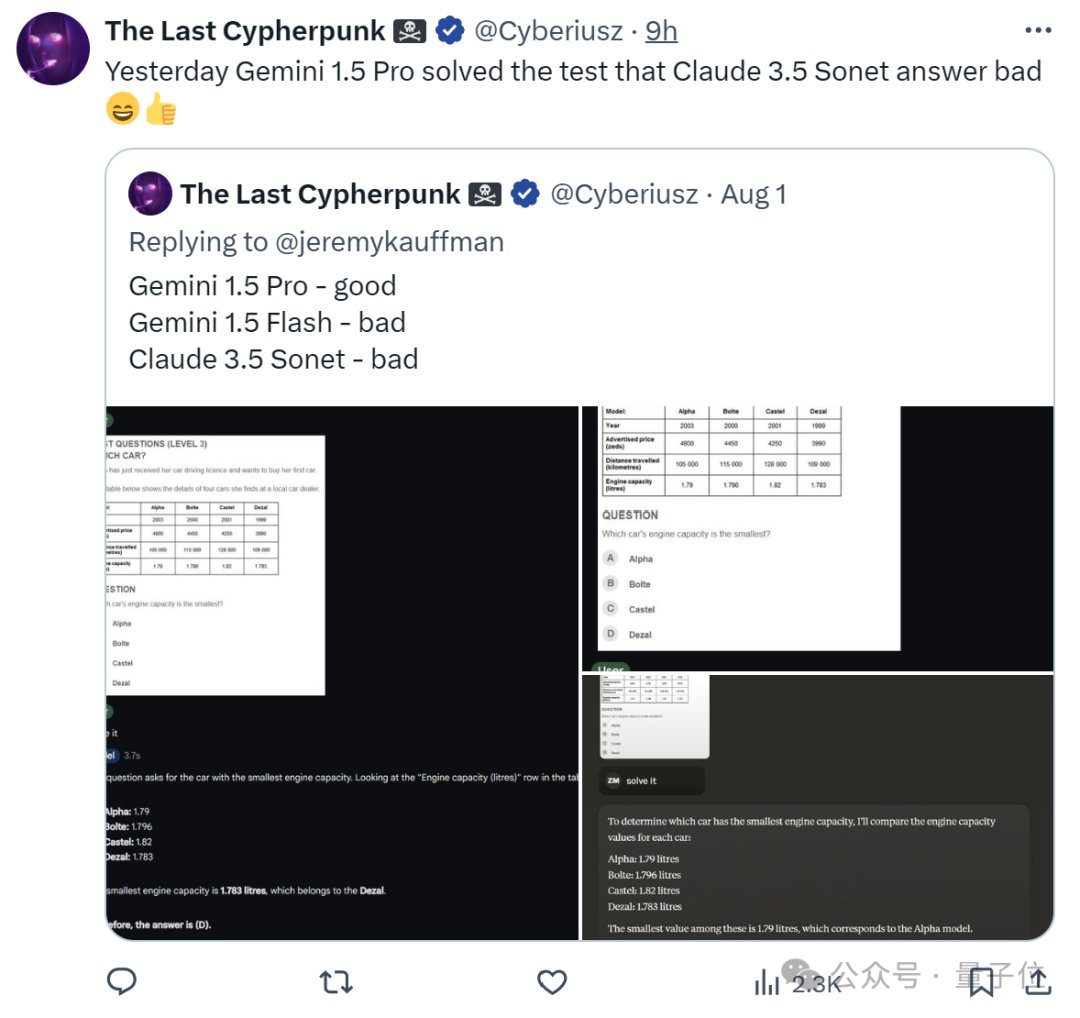
起猛了,GPT-4o被谷歌新模型击败,ChatGPT官号:大家深吸一口气
9
0
相关文章
近七日浏览最多
最新文章
标签云
微软
谷歌
腾讯
gpu
amd
亚马逊
字节跳动
知名企业
英伟达芯片
美国
罗杰施密特
美国广播公司
首席执行官
中国
黄仁勋
台积电
显卡
垄断
芯片
烟草
英伟达
特斯拉
科技股
美股
纳指
收盘
道指
微芯片
量子计算机
埃隆_马斯克
量子计算芯片
奥特曼游戏
宇宙
量子革命
超级计算机
佩斯科夫
俄罗斯政府
广播公司
youtube
俄罗斯
李世石
阿尔法狗
人工智能
哈萨比斯
诺贝尔奖
alphago
安卓
人社局
路透社
苹果手机
华为手机
国产手机
苹果公司
apple
三折叠屏手机
iphone
微信
ios
美国司法部
美元
chro
ibm
李开复
融资
linux
android
pi
搜索引擎
美国联邦
快科技
a股
etf
马斯克
abb
alphabet
奥尔特
期货
股票回购
100指数
美国政府
美国法院
jonathan
初创公司
john
siri
苹果
联邦法院
美政府