本文来自微信公众号:字母榜(ID:wujicaijing),作者:赵晋杰,编辑:王靖,题图来自:视觉中国
接到奥特曼警告信的第一时间,专注出海电商服务的大模型领域创业者高瑞麟,紧急召开了一场办公会,商讨是否需要将公司业务迁移到国产大模型上去的棘手问题。
“迁移,(担心)用户会不会继续买账;不迁移,继续(调用OpenAI API)的话,成本、合规风险等都在提高。”
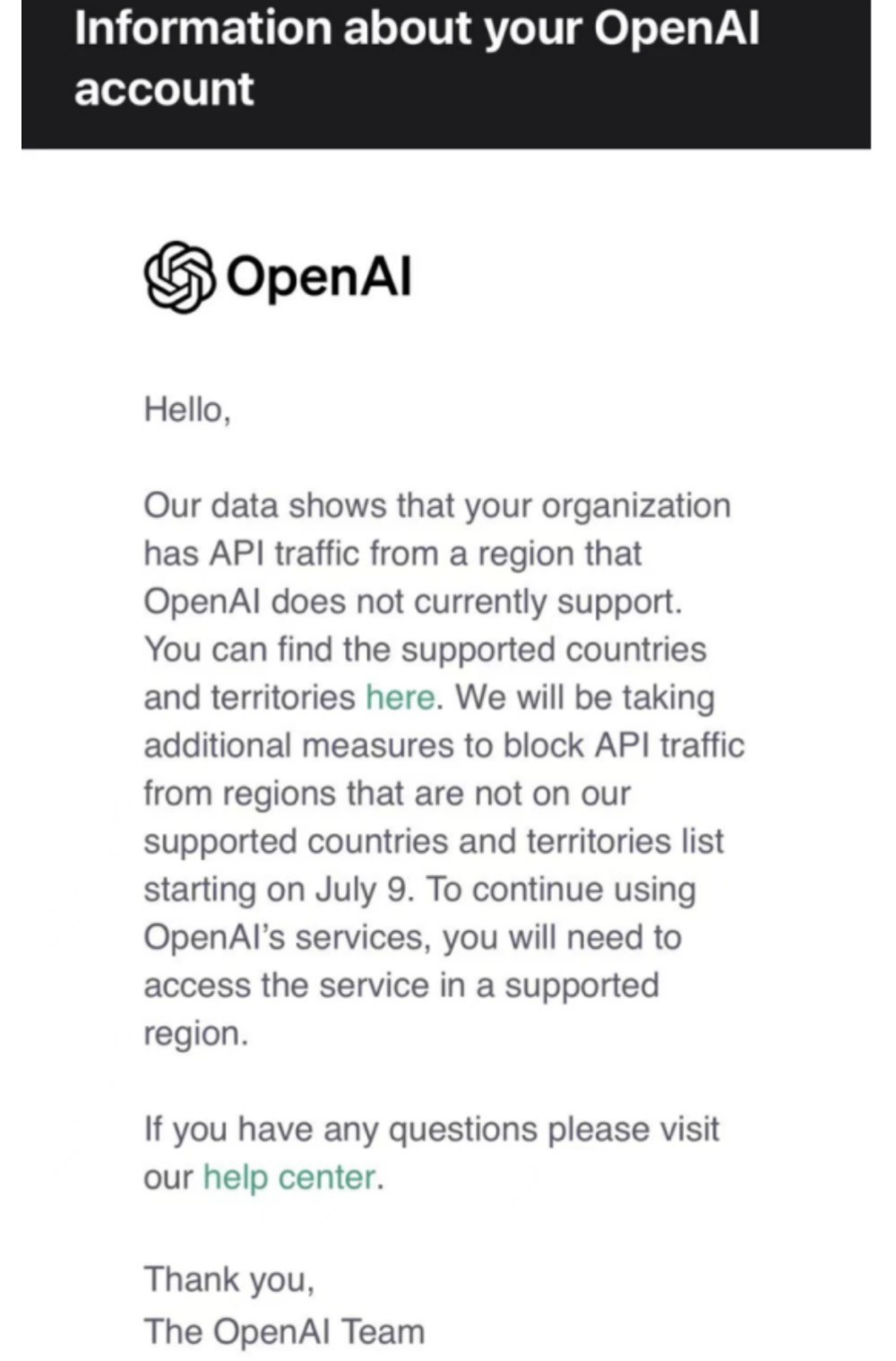
令高瑞麟陷入两难的,是在奥特曼领导下的OpenAI的一封推送邮件。在6月25日发出的邮件中,OpenAI表示,从今年7月9日开始,将阻止来自非支持国家和地区的API(应用程序接口)服务。受影响组织若希望继续使用OpenAI的服务,必须在其支持的国家或地区内访问。
这也意味着,不在支持地区范围内的中国大陆,将迎接OpenAI的“断供”风险。需要注意的是,ChatGPT爆红以来,OpenAI其实一直未曾开放过中国市场的服务。
国内大模型创业者李振告诉字母榜,当前国内想要访问OpenAI的API,一般有两个途径:一是直接向OpenAI官方申请,这种方式更多适合个人开发者;二是通过采购微软云服务,间接接入OpenAI服务,这也是当前国内唯一的合规渠道。据李振观察,目前微软云提供的OpenAI接入服务仍可以正常访问。
通过上述两种途径,围绕OpenAI的API,国内大模型玩家也由此发展出了两大应用场景:科技大厂用来帮助训练自己的大模型,在模仿的基础上追求赶超效果;中小企业则用来开发落地应用,在实际使用中向客户提供多样性选择。
对于更有实力和资源的大模型玩家而言,即便“断供”政策正式生效,也可能挡不住它们继续调用OpenAI API的行为。“在一个全球化的市场中,很难存在彻底隔断某一地区访问权限的可能性,就是需要穿越多少围栏的问题。”关注大模型投资的恒业资本创始合伙人江一说道。
一
进入2024年,即便已经出现了一众号称性能媲美GPT-4级别的国产基础大模型,但调用OpenAI技术的需求仍然存在。
在江一接触到的合作客户中,有人明确提出希望提供OpenAI技术选项,“面对更开放、更发散性的问答时,OpenAI展现出来的答案还是更强一些。”
这也促使一些应用开发商对不同的模型做起人为分割,简单的问题推理,以及涉及垂类行业问答的场景,优先调用国内大模型,偏复杂推理和分析的内容,就交给OpenAI。
具体运行环节,有点类似当前业内推崇的MoE混合专家模型逻辑,当客户提出一个问题后,借助机器学习的匹配算法,先将问题分类,从而基于分类结果匹配对应的模型服务商。但是否使用OpenAI服务,还取决于客户是否愿意为此多花钱。“充什么样的会员套餐,给你供应什么样的大模型选择范围。”李振解释道。
不同于应用开发者的具体使用需求,那些同样有着自研大模型野心的国内厂商,通过接入OpenAI技术,还能起到辅助刷榜的作用。
知名大模型测试集C-Eval就曾在官网置顶声明,称评估永远不可能是全面的,任何排行榜都可能以不健康的方式被黑客入侵,并给出了几种常见的刷榜手法,如对强大的模型(例如GPT-4)的预测结果蒸馏、找人工标注然后蒸馏、在网上找到原题加入训练集中微调模型等等。
站在OpenAI的肩膀上,从模仿借鉴中快速赶超,则是国内大模型玩家接入OpenAI技术的更重要目的。
去年12月份,字节跳动被曝光出正在研发一个名为“种子计划”(Project Seed)的AI大模型项目,但该项目在训练和评估模型等多个研发阶段调用了OpenAI的API,并使用ChatGPT输出的数据进行模型训练。
此举违反了OpenAI的使用协议,根据规则,OpenAI禁止使用输出开发竞争模型。因此,字节旗下部分GPT使用权限被OpenAI封禁。
字节官方坦陈,内部技术团队刚开始进行大模型的初期探索时,确实有部分工程师将ChatGPT的API服务应用于较小模型的实验性项目研究中,但“该模型仅为测试,没有计划上线,也从未对外使用”。
部分国产大模型在训练速度上快速起步的一大原因,同样离不开对国外大模型的借鉴。去年11月被传出套壳消息时,零一万物在回应字母榜中承认,在训练模型过程中,沿用了GPT/LLaMA的基本架构,但需要说明的是,借鉴架构并不能跟“套壳”或者“抄袭”直接划等号。
不过,这确实帮助零一万物缩短了模型研发时间。去年3月,李开复正式宣布将亲自带队,成立一家AI 2.0公司,研发通用大模型。经过三个月的筹办期,同年7月份,该公司正式定名“零一万物”,并组建起数十人的大模型研发团队。团队成型四个月后,零一万物便在11月份推出了“Yi”系列大模型产品,并借助Yi-34B霸榜多个大模型测试集。
二
在OpenAI“断供”危机之下,国产大模型的战略替代价值越发凸显。在李振看来,从经济账上考量,国内公司直接调用国产大模型会是更为划算的选择。
抢在企业迁移之前,一些追求更高收益的个人开发者,已经率先用国产模型替换掉了OpenAI。
2022年11月ChatGPT亮相后,受限于政策,一些人开始盯上国内想要尝鲜的用户,做起了卖号生意。当时,ChatGPT Plus官方订阅价格为一个月20美元,国内用户想要使用,收费一般为共享号(供4-6个人使用)一个月50元左右,独享号一个月170元左右。
但从2023年下半年开始,随着越来越多国产大模型的发布,加上用户对ChatGPT新鲜感的减弱,越来越多个人开发者已经将技术底座从OpenAI换成了国产平替,订阅价格也随之下降,有的连续包年仅需198元。
现在,在App Store应用商店中搜索“ChatGPT”,各类相似应用程序充斥其中,ChatGtp4o、ChatGp4、ChatGp4o、ChatBPT 4.0、ChatGTB4……

如今,OpenAI的“断供”之举,给国产大模型厂商提供了一次抢夺中小企业用户的迁移机会。
继5月份字节、阿里、百度、腾讯等掀起大模型价格战之外,从6月25日开始,一众国产大模型玩家又纷纷祭出了零成本迁移计划,再次加码性价比之战。
截至目前,包括智谱AI、百度、阿里、腾讯、百川智能、零一万物、商汤科技、月之暗面等均已推出了OpenAI零成本迁移计划。为加速用户“搬家”,部分国产大模型还额外附送1千万乃至1亿Tokens,并配套调用、迁徙、训练等多项免费服务大礼包。
三
便宜,只是鼓动用户迁移的必要条件。想要真正赢得用户的青睐,国产大模型还需要做到更好用。
去年曾喊出史上最大降价的阿里云,并未能借助价格战换来新的增长。聚焦到国内公有云市场,阿里云市场份额不增反减。IDC发布的《中国公有云服务市场(2023下半年)跟踪》报告显示,2023下半年IaaS市场中,阿里云市场占比27.1%,位居第一。但在2023上半年中国IaaS市场中,阿里云市场份额则为29.9%。
更何况,在国产大模型降价的同时,OpenAI们也在降价。按奥特曼的话说,“OpenAI也可以将非常高质量的AI技术的成本降至接近零……”
想要增强大模型底座的产品吸引力,除了价格之外,更重要的比拼则在数据端。
2020年发布GPT-3时,OpenAI曾详细公开了模型训练的所有技术细节。中国人民大学高瓴人工智能学院执行院长文继荣表示,国内很多大模型其实都有GPT-3的影子。但随着OpenAI在GPT-4上一改开源策略,逐渐走向封闭,一些国产大模型就此失去了可供复制的追赶路径。
此后,各家大模型拉开技术差距的重点,越来越多体现在训练方法、数据配比、数据工程、细节参数、训练过程监测技巧等细节之中。
即便在模型框架相同之下,不同的数据来源和数据训练方法加持下,最终训练出来的大模型性能依然会表现各异。“前大模型时代,AI的主流是以模型为中心的单任务系统,数据基本保持不变。进入大模型时代,算法基本保持恒定,而数据在不断增强增大。”在产业专家刘飞看来,相比算法和算力,数据可能是眼下阻碍国产大模型追赶OpenAI步伐的更大鸿沟,“魔鬼都藏在这些数据训练的细节里。”
在国内大模型纷纷跨入万亿参数时代之后,对数据采集和训练的能力考验再次提升。参数量的大小与最终模型呈现的效果之间,两者“投入产出并不成正比,而是非线性的”。刘飞表示,“数据多只是一个定性,更重要的是考验团队数据清洗的能力,否则随着数据增多,数据干扰也将随之变大。”
本文来自微信公众号:字母榜(ID:wujicaijing),作者:赵晋杰,编辑:王靖
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com