友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
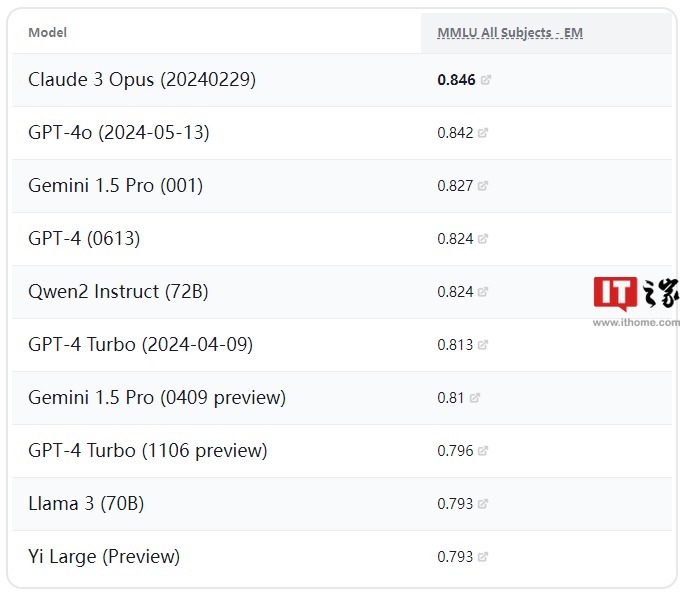
斯坦福大模型评测榜 Claude 3 排名第一
56
0
相关文章
最新文章
标签云
教授
研究生
哈佛大学
纽约大学
斯坦福大学
院士
美国
李飞飞
ai教母
顶尖科学家榜单
录用
镇政府
郭沫若
向阳镇
安徽省
灵璧县
乡镇公务员
香港
学霸
斯坦福
联合国
奥运会
世乒赛
乒乓球
美国队
美国历史
乒乓球队
中国人民大学
花样滑冰
跆拳道
中国队
夺冠
奥运
人工智能
初创公司
研究院
肺部
健康
病变
德克萨斯
美国大学
密歇根大学
计算机科学
github
特斯拉
alex
操作系统
adobe
亚瑟
中国政府
科技
经济学人
半导体
中国
turbo
公务员
科创板日报
机器人
上海证券
中科大
学生时代
英格拉姆
哈里森
国际篮联
nba
北卡罗来纳大学
高校
贝索斯
前妻
新京报
考试
博士
县乡镇
中国文化
刘雪华
马克
中国传统文化
马斯克
chris
融资
千元机
sgs
华为
游戏
生存游戏
模拟游戏
虚假宣传
小米手机
miui
小米公司
卡顿
谷歌
纽博格林赛道
液晶仪表
gts
保时捷
空气动力学
阿里
imax
腾讯
panamera
米其林
v8发动机
涡轮增压
混动系统
电动机
pilot
微软
azure
oled
奔驰amg
porsche
奥特曼
v8
沃恩
机器狗
红米手机
x50
电池容量
联发科天玑
redmi
曲面屏
ip68
保时捷911
chro
北约
朝鲜
德国
印第安人
美国政府
寄宿学校
南北战争
斯大林
罗斯福
白宫
共和党
美国总统
美国大选
詹姆斯
杜兰特
里根
贾玲
gaga
雷军
沉默的大多数
勒布朗
朝中社
马龙
护卫舰
印度
印度制造
安保
美国特勤局
罗纳德
内塔尼亚胡
苏纳克
印度人
英国
总统大选
招生
本科
名校
曹德旺
投档线
福耀科技大学
霍启刚
霍震霆
u17
小姐姐
林志玲
东京奥运
里约奥运
邓丽君
赵涛
比尔盖茨
贝佐斯
吊带
就业
家长
弗朗西斯科
牛津大学
sat
商业模式
重点大学
清华
哈佛
创业时代
大长腿
华纳兄弟
英伟达
黄仁勋