提到AI PC,大家首先会想到什么?
是那些内置NPU,能够以高能效常时驱动AI大模型,享受智能语音、智能摄像头,并在部分日常软件中得到额外加速效果的家用电脑。

又或者是那些有着几千上万个节点、插满了AI加速卡,为云端AI算力提供支撑,甚至本身就在训练、产出大模型本身的超级电脑和服务器。

诚然,以上我们提到的这两种类型的电脑,其实都可以算作“AI PC”。但除了它们之外,对于那些有AI创制需求,想要自行生产AI内容、甚至是训练AI模型的用户来说,他们还有一种不容忽视的产品形态选择、那便是“工作站电脑”。

而且最有意思的是,对于某些特定的用户需求来说,顶级的工作站平台在性能上甚至可以做到“下打家用PC、上揍多路服务器”。

没错,我们上面说的正是英特尔目前最新的第四代至强W工作站处理器。就在2024年3月20日,我们三易生活也近距离了解和体验了英特尔这一代的“单路工作站最强芯”。
不止单路最强,至强W更是究极个人电脑的核心
如果你是一位电脑发烧友,那么想必就不会对至强W-3175X和至强W9-3495X这两款CPU感到陌生。它们之中,前者是曾经的8K剪辑“神U”,后者则正是最新架构的单路顶级工作站CPU方案之一。
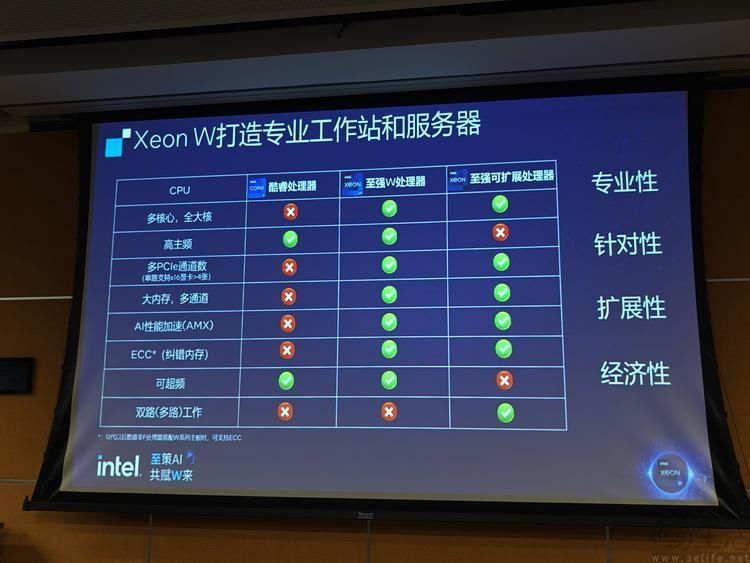
为什么至强W敢称“单路最强”?从上面这张简单对比图就可以看到家用级的酷睿、至强W,以及服务器上至强可扩展CPU之间的区别。
很显然,与酷睿处理器相比,至强W使用了全大核架构,能够提供多至60核、120线程的单路全大核算力。与此同时,它还拥有酷睿所不具备的AMX矩阵加速指令集,经英特尔的实测显示,能够实现比没有该指令集的CPU提高四倍的AIGC计算效率。

不仅如此,至强W还具备多达112条直连CPU的满血PCIE5.0总线,相比普通的家用平台,可以连接多个显卡、AI加速卡,而不会出现带宽瓶颈。再加上多达8条支持ECC(错误校验)的内存通道,既能为超大计算量提供足够的带宽,也能提高系统整体稳定性,避免出错。

而与服务器上的至强可扩展CPU相比,至强W也有一个显著的优势,那就是它拥有高得多的主频,甚至支持用户自行超频,以压榨出更高的单核与整体性能。这样一来,也就使得至强W实际上同时具备了“超强专业生产力”和“超强本地娱乐性能”,堪称是工作娱乐兼顾的梦幻PC核心。
为何AIGC需要至强W?技术和市场的双重驱动
看到这里可能有的朋友会说,至强W虽然很强,但在预算无上限的情况下,直接用双路甚至四路的服务器或者是搭载酷睿i9-14900KS的顶级游戏主机,难道不是会有着更多的核心/更高的主频,为什么一定要用单路工作站CPU呢?

首先众所周知的是,目前使用电脑运行、最火热的“生产力项目”,可能就莫过于AIGC了。但AIGC本质上其实是一种超大规模的并行计算。这就意味着只要有更多的CPU核心、更大的内存、更多的加速卡和显存,AIGC的速度确实就能成倍地提升。比如根据英特尔的测试结果显示,四GPU的AIGC视频生成确实就是单GPU差不多四倍的速度。
但家用的酷睿处理器、哪怕是i9,也只有两条内存通道,最多不过支持256GB内存以及一张满速的显卡通道。

相比之下,至强W处理器则可以支持单路4TB的内存,以及至多6张、甚至8张满速的显卡并联。再加上独有的AMX矩阵加速指令集的加成,最终所带来的性能提升显然就不是酷睿i9-14900KS那一点点更高的主频,所能够追上的。
与此同时,与服务器级别的至强可扩展处理器相比,至强W还有一个难以忽视的巨大优势、那就是它的销售方式。

对于传统服务器来说,消费者想要购买其实是一件非常困难的事情,因为通常没法直接以个人名义订购,而是要以企业的身份去接洽少数那几个品牌的销售代表,然后在少数几款产品组合里进行选择、定制。它们不只非常昂贵,很多时候还会带有个人创作者、或是小微企业完全用不到的功能。甚至在一些具体的配置(比如内存、SSD)上,受限于这些服务器厂商自己的供应链制约,它们反而不能达到当前零售市场里的最高水准。

但工作站的情况就完全不一样了,因为就在几年前,英特尔方面就已经放开了至强W处理器在零售市场的销售权限。对于普通消费者来说,现在可以很简单地在通路市场购买配备至强W处理器的电脑,而且不仅限于少数传统品牌,还会有很多其他的供应商可以提供带有他们特定软件的定制至强W工作站。
根据英特尔方面公布的相关信息显示,现在已有50家左右的OEM、ODM,以及ISV厂商可以提供这种定制的至强W工作站,远超以往仅仅两三家的选择自由度。

甚至对于部分发烧友来说,他们还可以像是“攒机”那样,直接购买零售版的至强W处理器、购买对应的W790主板,然后搭配高主频内存、显卡、顶级SSD,来组成自己的“梦幻配置”。而这种自由度,更是服务器版本的至强所完全不可能提供的方案。
创制、驱动和推进AI大时代,英特尔还有更长远的打算
当然,说到英特尔的AI平台,许多朋友可能还会想到英特尔的酷睿Ultra处理器、ARC显卡、Movidus VPU(也就是现在的NPU),以及Gaudi AI加速卡。

不难发现,英特尔实际上很可能拥有目前行业里形态最全、架构覆盖最广的AI算力组合。从最上游的超大规模AI模型训练到专业级的AI内容生成,再到消费级产品上的低功耗实时AI优化,英特尔都能提供相应的解决方案。
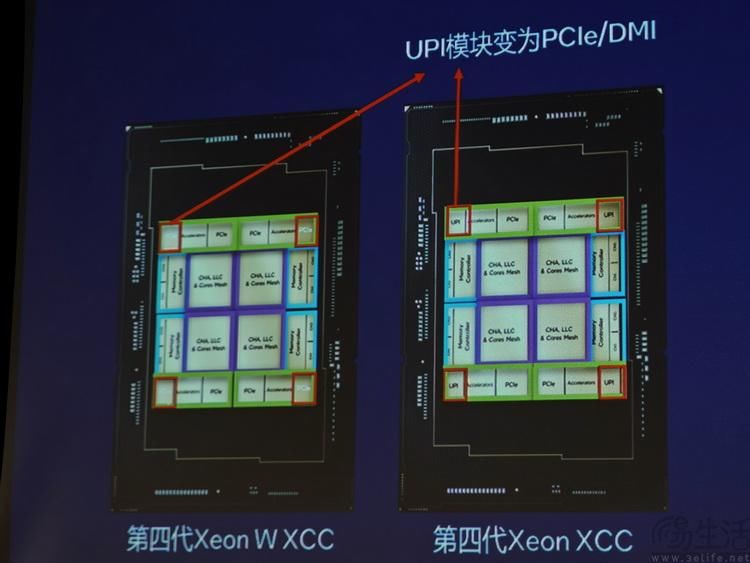
但更为重要的是,一方面通过自研、并且已经开源的OneAPI方案,英特尔实现了不同架构(甚至包括竞争对手的架构)、不同AI软件的“相互兼容”。同样的AI程序在至强W上可能是靠几十个CPU内核驱动,而到了搭载酷睿Ultra的笔记本电脑上,就能自动调用CPU、GPU与NPU的异构算力。
另一方面,根据英特尔方面此前在2023年底发布的相关技术白皮书显示,他们有望在下一代的至强架构上首次实装全新的APX指令集体系,并很快将其普及到更新一代的酷睿平台上中。
众所周知,目前酷睿平台并不支持AVX512和AMX这两个高性能加速指令集,因此全新的APX指令集体系不仅将有望大幅增加未来酷睿处理器的AI性能,更有可能会在一定程度上弥合“酷睿”与“至强”两条产品线在应用程序代码层面的差异,从而进一步增强英特尔整个计算体系内从创作到应用端的代码兼容性和执行效率。

在我们三易生活与英特尔方面相关人士的沟通中,对方表示,从头开始建立自己全面的技术体系,是目前英特尔在这个“AI大时代”的重要目标。而从他们目前的产品组合、技术规划,乃至市场策略来看,英特尔也确实正在用自己的节奏,走出一条此前并没有其他企业走过的、全链路的AI计算体系之路。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com