来源:字母榜(ID:wujicaijing) 作者:毕安娣
OpenAI似乎已经在为Sora降世预热了。
当地时间3月13日周三,OpenAI首席技术官米拉·穆拉蒂(Mira Murati)接受了《华盛顿邮报》的视频专访。
视频不长,只有不到11分钟,但全部围绕OpenAI的文字到视频工具Sora,穆拉蒂透露了一个重要的消息。当被问及Sora何时面向公众推出时,穆拉蒂回答:“我想肯定是在今年,但可能是几个月后。”
除此之外,穆拉蒂还回答了Sora的特别之处、如何修正瑕疵、是否会包含音频、训练数据来自哪里等若干问题。给出的答案有的笼统,有的不乏诚意。
距离OpenAI突然展示Sora,已经过去一个月了。Sora演示视频的时长和效果惊艳世人,迅速成为舆论宠儿。但Sora也带来太多问号:没有明确的发布时间、只对少数人开放测试、对训练数据来源三缄其口。
但现在,OpenAI似乎在一点点释放更多信息。
作为OpenAI最重要的高管之一,穆拉蒂的话自有其分量。而就在前几天,Sora的三位核心团队成员也出现在科技播客WVFRM中,接受了专访。
此外,另一档头部播客主理人Lex Fridman也已经官宣将很快邀请OpenAI的CEO山姆·奥特曼(Sam Altman)上节目,正在征集粉丝关心的问题。上次奥特曼出现在这档播客中是一年前,GPT-4发布后不久。
也许Sora降世,真的已经进入最后的倒计时。
A
有些问题,穆拉蒂乐于回答。
在这次的专访中,主持人拿出了几个Sora生成的视频,并对穆拉蒂进行了提问。
一个不可忽略的问题是,Sora为什么效果那么好?对于一则“两个职业女性,30多岁,坐在一个灯光明亮的工作室中接受新闻采访”的指令,主持人尝试了Sora和Runway两个产品。Sora生成的视频几乎可以以假乱真,但Runway的视频则不仅有奇怪且数量过多的手指,且在动作时有明显的嘴部扭曲,看起来颇为诡异。
穆拉蒂解释,Sora基于扩散模型,通过分析大量视频学习识别物体和动作。当给定文本提示时,Sora能通过定义时间线和逐帧添加细节来创建场景,生成的视频在平滑度和现实感方面很出色。
但主持人也把一些有明显瑕疵的视频摆在穆拉蒂面前,比如行进中的汽车突然从黄色变成了银色,或者Sora没有按照指令生成“机器人夺过摄像机”的画面,而是让机器人把那摄影机的女人直接融合了。
穆拉蒂表示,OpenAI目前正在探索如何使Sora成为可以用户可以用来编辑或创作内容的工具。翻译一下就是:Sora不完美,在想办法了。
对于另一个外界关心的问题,即Sora会不会包含音频(Sora目前的视频都是无声的),穆拉蒂也透露了一些信息——目前还没有整合音频,但这是OpenAI会考虑的方向。
与此同时,针对外界对安全的担忧,穆拉蒂也没有回避。
穆拉蒂表示,OpenAI目前还没有明确决定Sora可以生成的视频范畴,但是会借鉴其文生图模型DALL-E的做法,比如不会生成政治人物的形象。当主持人问及裸体画面时,穆拉蒂表示不确定,艺术家可能会希望有一些可以调控的创作选项,目前OpenAI正在与不同领域的艺术家和创作者合作,试图搞清楚Sora应该提供什么水平的灵活度。
至于对于“现实不存在”的恐惧,即人们将难以区分真实与AI内容,穆拉蒂回答这正是OpenAI还未部署Sora的原因。目前,Sora生成的视频都会打上水印,但这似乎还不够好。穆拉蒂透露,Sora的视频将包含元数据来表明来源。OpenAI也用安全人员测试Sora,试图引出漏洞、偏见及其他有害结果。
作为OpenAI的CTO,穆拉蒂强调对于安全问题的重视。她表示“金钱”和“安全”并不是一道难做的选择题,如何解决安全和社会问题才是让她睡不着觉的难题。
B
不过,也有穆拉蒂不太想触碰的话题。
在外界都关心的训练数据来源问题上,不仅Sora团队接受专访时表示不方便说得太细,穆拉蒂也再一次打了太极。
主持人在测试Sora时发现了有趣的细节。比如在“海底珊瑚礁中,一只美人鱼和一只螃蟹助手在一起评论一部智能手机”的视频里,在没有相关提示词的情况下,螃蟹有长条状的双眼和两撮胡子,酷似动画片《海绵宝宝》里的蟹老板;另一则公牛在瓷器商店里的视频,公牛的形象则也酷似《公牛历险记》里的。
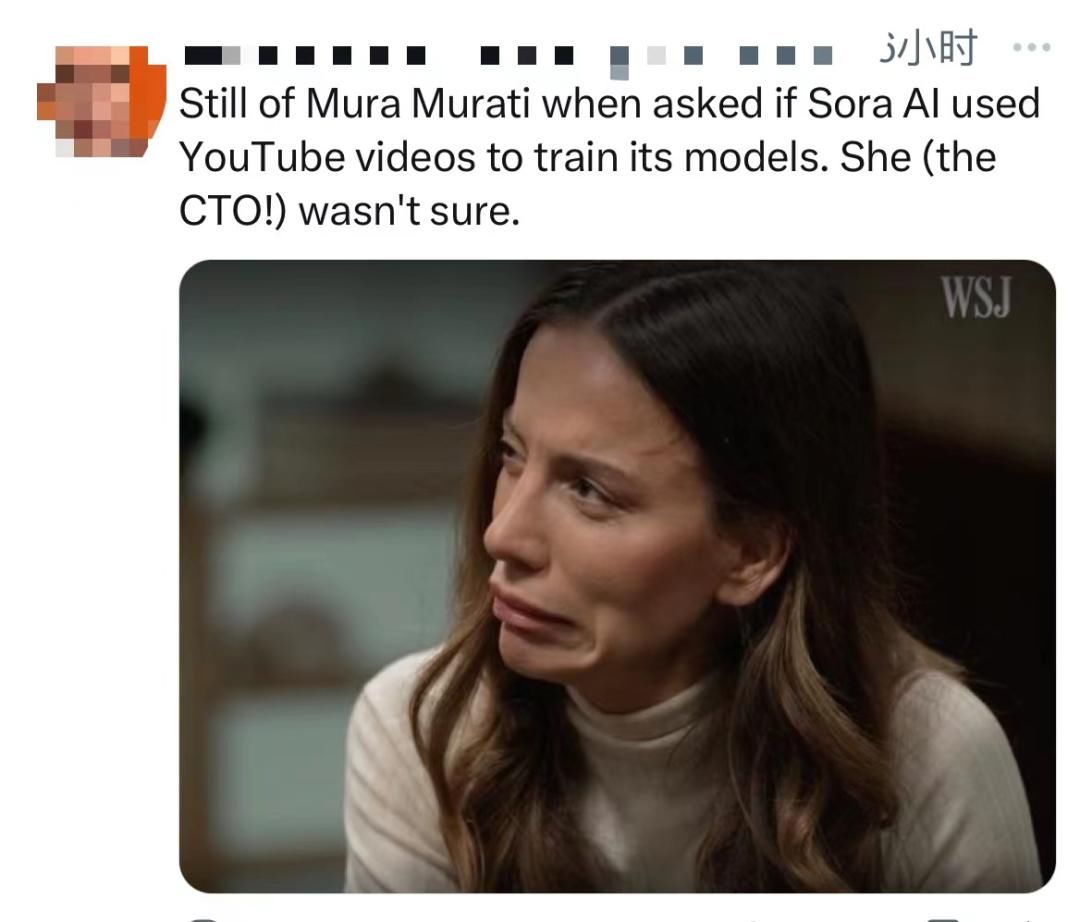
问:有没有用YouTube上的视频?
穆拉蒂答:我其实不确定。
问:好吧。那Instagram和Facebook上的视频呢?
穆拉蒂答:如果这些视频是公开可用的,那可能在训练数据里。但我不确定。
总之,别问,问就是不知道、不明白、不清楚、不确定,问就是也许吧、可能是、看情况。
穆拉蒂倒是确认了Sora的训练数据包含图片网站Shutterstock的内容。这没什么意外的,去年7月,Shutterstock就宣布把和OpenAI的合作延长六年,允许后者使用其平台内的图片、视频、音乐来训练AI模型。
这样的回答难以令人满意,网友截图穆拉蒂在听到问题时的表情,嘲讽她的“不确定”。
对于训练数据的来源问题,OpenAI保持谨慎在意料之中。
自ChatGPT面世,OpenAI已经多次因训练数据版权问题惹上麻烦。最近的是今年《纽约时报》以侵犯版权为由起诉OpenAI及其合作伙伴微软,随后多家数字新闻媒体加入起诉OpenAI侵权的队伍。此外,还有数名演员、记者、作家以及美国作家协会对OpenAI提出诉讼,称该公司的大型语言模型参与了“大规模的系统盗窃”。
更糟糕的是,Sora还没有面向公众推出,就已经被监管机构盯上。近日,意大利数据保护机构Garante发布公告,称已对Sora展开调查,内容包括Sora的算法训练方式、训练过程中手机和使用了哪些数据等。意大利数据保护机构是欧洲各国中最活跃的监管机构之一。
C
训练数据来源、安全问题都备受瞩目,再加上2024年是美国大选之年,重重阻碍摆在Sora面前,OpenAI也着急。
一方面,OpenAI急于重申其在AIGC领域的领先地位。
就在3月初,硅谷AIGC独角兽、OpenAI的劲敌Anthropic推出新一代大语言模型Claude 3系列。其中最智能的Opus已经在多项基准测试中打败GPT-4。甚至在发布后不久,Claude 3已经具备意识的传闻就在网络上蔓延。
也许是感觉到了压力,OpenAI的GPT-4.5 Turbo产品页面一度悄然出现在多个搜索引擎中,疑似要提前发布(原定今年6月)。虽然链接已经在消息被传出后下架,但奥特曼也在X社交平台上回复一条催促OpenAI尽快发布新产品的消息下回复:“耐心点,这值得等待。”让外界更加期待。
此外,微软在3月13日宣布,将免费版Copilot升级到GPT-4 Turbo模型。去年11月OpenAI宣布推出GPT-4 Turbo,微软彼时将其接入Copilot,但仅供订阅用户使用,每月20美元。
若GPT-4.5 Turbo提前发布,Sora又在不久的将来与公众见面,将成为OpenAI的完美组合拳。
另一方面,OpenAI也需要公众注意力重新聚焦在其产品上。
过去的几周,马斯克起诉OpenAI,称其违背了创始协议,并请求法院令其开源。一不做二不休,马斯克甚至开源自家xAI公司的大模型产品Grok,再次将OpenAI推向不仁不义不Open的尴尬处境当中。
OpenAI已经对此事做了公开回应,并且提交了法律文件。此外,OpenAI还恰逢其时地公布了对于去年年底OpenAI“高层事变”的调查结果。
在那场高层震荡中,奥特曼被踢出董事会并卸任CEO,又在三日内归来,几乎重新组建了董事会。马斯克在起诉书中将该事件描绘成了一场阴谋,称奥特曼的新董事会缺乏专业背景,为了和微软的合作关系永远不会宣布AGI(通用人工智能)的到来。
OpenAI给出的调查结果认为事件只是出于旧董事会和奥特曼的信任问题,与此同时公司宣布四名新董事会成员。其中奥特曼再次进入董事会,其他新成员也不乏技术背景,间接驳斥了马斯克在诉状中的“阴谋论”。
OpenAI想要给去年的闹剧盖棺定论,但“OpenAI变CloseAI”的梗依然在网络流传,人们对该事件的关注犹在。
在Lex Fridman宣布将再度邀请奥特曼参加其播客节目的消息评论区,粉丝最关心的问题依然是:曾被媒体报道为出于对AGI的恐惧而推动“事变”的伊利亚·苏茨克维(Ilya Sutskever)去哪儿了?他到底知道什么秘密?

也许当用户可以用Sora制作一部关于“事变”的“内幕电影”时,OpenAI就不用回答这个问题了。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com